演示在这里:https : //stupefied-curran-2254b8.netlify.com/
您是否曾经去过TLDR(太懒了,没看过)来阅读在线文章或任何某种形式的网页…,
并希望您的浏览器会为您阅读?
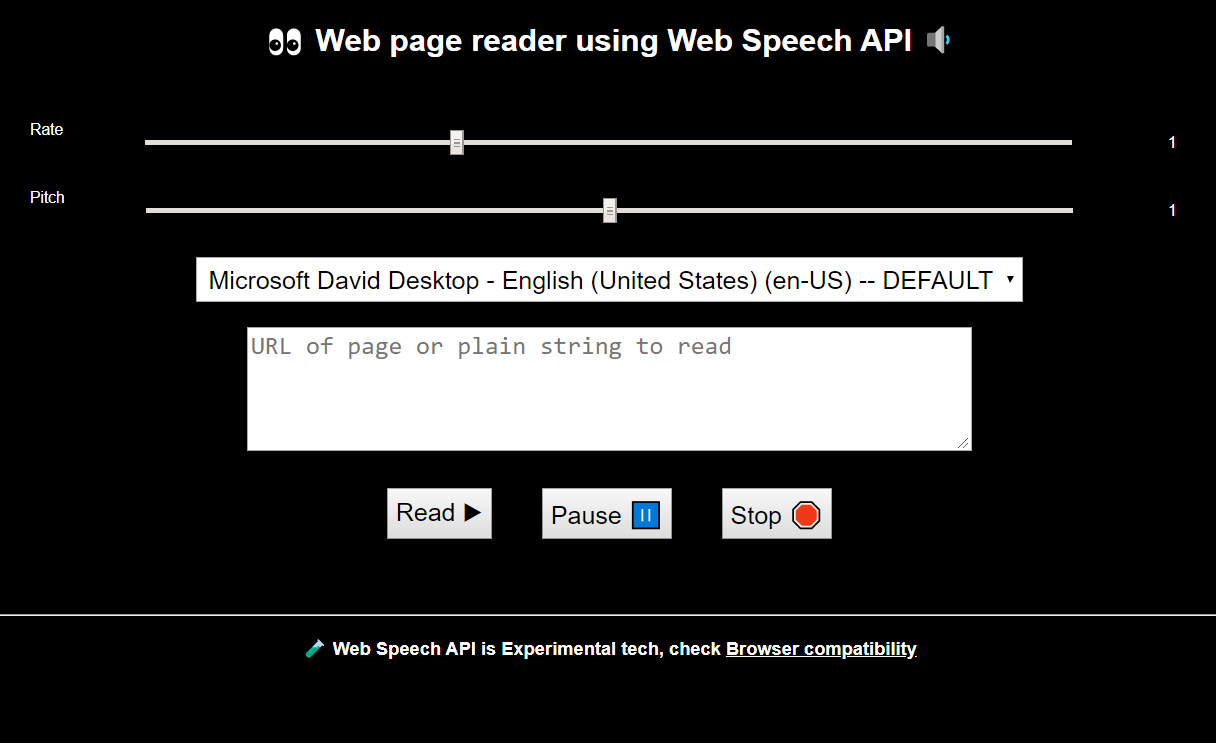
好吧,你很幸运!我建立了一个网页阅读器。😆
只需在输入中复制粘贴URL或一些文本,它就会为您阅读!
好吧,可读部分至少 😅

Speech Web Speech API
我使用了本机浏览器的Web Speech API中的Speech Synthesis。
这是一项实验性技术,但是现在您很有可能会在浏览器中找到它!
实际上,从Chrome 33 +,Firefox 49,Edge 14开始,我们所有人都拥有此功能。但是如果您使用的是tamagochi🐰:caniuse Web Speech API,请在此处检查。
语音输入
用户输入是以下HTML元素:
textarea用于读取的URL /文本select语音输入range音调和速率输入
检查textarea内容是纯文本还是URL。
的速率(在说话的速度有多快进)的范围为0.5至2
的间距(高度或语音的lowness)的范围从0到2
的语音选择提供可从系统的声音。
🎤 SpeechSynthesisVoice
可用声音因设备而异,并且通过来获得
speechSynthesisInstance.getVoices()。
这将返回所有SpeechSynthesisVoice对象,这些对象将填充到选择选项中。
用户选择其中一项,或保留默认值。
现在,使浏览器真正交谈的是SpeechSynthesisUtterance对象。

🗣 SpeechSynthesisUtterance
甲SpeechSynthesisUtterance对象(utterance)是像个人讲话请求,这是我们以字符串初始化和连接所有的语音元素,如语音,速率和音高。
最后,通过触发发声speechSynthesis.speak()。
finishUtteranceCallback文本完成时,还提供了A 来启用播放按钮和其他控件。
此逻辑封装在 speak(string, voice, pitch, rate, finishUtteranceCallback)
speak(string, voice, pitch, rate, finishUtteranceCallback) {
if (this.synth.speaking) {
console.error('🗣 already speaking');
return;
}
if (string) {
const utterance = new SpeechSynthesisUtterance(string);
utterance.onend = () => {
console.log('utterance end');
finishUtteranceCallback();
};
utterance.voice = voice;
utterance.pitch = pitch;
utterance.rate = rate;
this.synth.speak(utterance);
}
}
所有这些功能都包装在中,WebSpeechApi以保持模块化。📦
有关语音语音的详细信息,请查看:MDN语音语音。
该MDN页面上有一个很棒的摘要以及创建该应用程序的示例。请也检查一下!
🌐URL检查
用户可以在上输入URL或文本textarea进行阅读。
但这如何检测它是否是URL?
一个简单try-catch的窍门。
// simple check if valid URL
try {
new URL(urlOrText);
isUrl = true;
} catch (error) {
// not a URL, treat as string
isUrl = false;
}
如果是纯文本,则将其直接传递到speak()。
如果确实是URL,则GET请求加载页面并刮除可读元素。
🕷️网页抓取使用cheerio和axios
cheerio是jQuery的一个子集,可快速,轻松且灵活地解析HTML。
(很简单,就像cheerio.load(<p>some html</p>))
axios 是一个基于Promise的客户端,用于从API中获取内容,在这种情况下,可以从网页获取完整的HTTP get响应。
结合起来,这就是我获取页面的所有“可读”元素的方式。
const getWebsiteTexts = siteUrl => new Promise((resolve, reject) => {
axios
.get(siteUrl)
.then((result) => {
const $ = cheerio.load(result.data);
const contents = $('p, h1, h2, h3').contents(); // get all "readable" element contents
const texts = contents
.toArray()
.map(p => p.data && p.data.trim())
.filter(p => p);
resolve(texts);
})
.catch((err) => {
// handle err
const errorObj = err.toJSON();
alert(`${errorObj.message} on ${errorObj.config.url}\nPlease try a different website`);
urlOrTextInput.value = '';
finishUtterance();
});
});
一些网址出错了,因此我们可以捕获错误,alert()用户,清除文本区域并重置表单输入。
为什么某些网址不起作用?

ORS CORS政策
刮板无法解析所有网站。
实际上,许多网站(请尝试中型文章)都有CORS政策。
因此,在某些网站上您会收到这样的错误。意味着只有Same Origin可以执行来自Webapp脚本的GET请求。
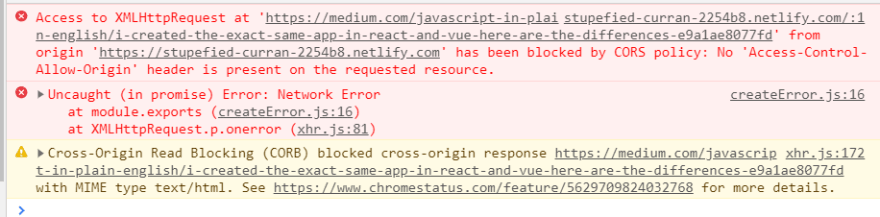
CORS policy: No 'Access-Control-Allow-Origin'
- 请注意,
cURLPostman仍然可以在这些站点上工作,只是不能从Javascript这样工作。
这是从我们尝试读取的站点的服务器上启用的,因此我们无能为力,只能转到另一个页面。😢
这是CORS的一个不错的总结:

dev.to页面可以工作!试试看🎉。
谢谢dev.to让我们刮 scrap
▶️播放,暂停,重新启动
最后,我添加了一些基本的播放控件。

这是根据的当前状态启动或恢复的播放功能。其他控件只是除了暂停和停止。pausedspeechSyntesisdisabled
playButton.addEventListener('click', () => {
if (speechApi.synth.paused) {
speechApi.synth.resume();
} else {
// start from beginning
read();
}
playButton.disabled = true;
pauseButton.disabled = false;
stopButton.disabled = false;
rateSlider.disabled = true;
pitchSlider.disabled = true;
voiceSelect.disabled = true;
urlOrTextInput.disabled = true;
});
在禁用了不同控件的情况下,暂停和停止大致相同。
and建立和部署
我使用parcel了无麻烦的无配置捆绑程序,对于像这样的原始JS项目,这非常简单。
最后,Netlify可简化静态部署。在Netlify中设置Github存储库后,它只是选择了dist/Parcel构建的文件夹。
做完了!
📃改进
这是一个快速的项目,因此肯定可以使用一些改进(和更正)。
💻这是代码。希望这会激发一些想法,并帮助您开始一些很棒的文本到语音项目。😁
使用Web Speech API的Web阅读器
现场演示https://stupefied-curran-2254b8.netlify.com/
开发者
npm run dev
建立
npm run build
有什么建议,评论,问题吗?
(例如以更好的方式检查string是否为URL😅),
请在评论中让我知道!
谢谢,祝您阅读愉快!
