这篇教程将介绍如何使用Python扒妹子图片并自动发布的自己的wordpress图片网站,图片将保存到chevereto图床,图站分离。所以要完成此教程的前提是你已经拥有一个chevereto图床网站和一个wordpress网站。wordpress网站的搭建非常简单,这里就不介绍了,另外如何搭建chevereto图床网站,可以参考我的这篇博客:chevereto图床程序免费版安装教程。
教程的爬虫目标网站是:http://www.mm131.com ,爬虫的源码如下:
#!/usr/bin/python
#-*- coding : utf-8 -*-
import mimetypes,json
import requests
import re,os,threading,time,pymysql
class wordpress_post:
def __init__(self,tittle,content):
self.tittle=tittle
self.content=content
def mysql_con(self):
conn = pymysql.connect(host='', port=3306, user='', passwd='', db='', charset='utf8') #在此修改数据库信息
return conn
def up(self):
times=time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
sql="INSERT INTO wp_posts(post_author,post_date,post_content,post_title,post_excerpt,post_status,comment_status,ping_status,post_name,to_ping,pinged,post_modified,post_content_filtered,post_parent,menu_order,post_type,comment_count) VALUES ('1','%s','%s','%s','','publish','open','open','%s','','','%s','','0','0','post','0')" % (str(times),str(self.content),str(self.tittle),str(self.tittle),str(times))
return sql
def cat(self,ids,cat):
sql="INSERT INTO wp_term_relationships(object_id,term_taxonomy_id,term_order) VALUES (%s,%s,'0')"%(ids,cat)
return sql
def close_mysql(self,cursor,conn):
conn.commit()
cursor.close()
conn.close()
def upload(files):
APIKey = "" #在此修改apikey
format = "json"
url = "http://yoursite/api/1/upload/?key="+ APIKey + "&format=" + format #在此修改图床地址
r = requests.post(url, files = files)
time.sleep(1)
return json.loads(r.text)
def formatSource(filename):
imageList = []
type = mimetypes.guess_type(filename)[0]
imageList.append(('source' , (filename , open(filename , 'rb') , type)))
return imageList
return imageList
class myThread (threading.Thread):
def __init__(self, url, dir, filename):
threading.Thread.__init__(self)
self.threadID = filename
self.url = url
self.dir = dir
self.filename=filename
def run(self):
download_pic(self.url,self.dir,self.filename)
def download_pic(url,dir,filename):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36Name','Referer':'http://www.mm131.com/'}
req=requests.get(url=url,headers=headers)
if req.status_code==200:
with open('temp/'+str(filename)+'.jpg','wb') as f:
f.write(req.content)
def get_page_url_info(flag):
infos=[]
if flag==1:
url='http://www.mm131.com/xinggan/'
else:
url='http://www.mm131.com/xinggan/list_6_'+str(flag)+'.html'
get=requests.get(url)
infos=re.findall(r'<dd><a target="_blank" href="http://www.mm131.com/xinggan/([0-9]*).html"><img src=',get.text)
return infos
def get_page_img_info(a):
getpage=requests.get('http://www.mm131.com/xinggan/'+str(a)+'.html')
tittle=re.findall(r'<h5>(.*)</h5>',str(getpage.content,'gb2312',errors='ignore'))
pages=re.findall(r'<span class="page-ch">共(.*?)页</span>',str(getpage.content,'gb2312',errors='ignore'))
return tittle,pages
def get_img(a,page,tittle):
threads=[]
download_url='http://img1.mm131.me/pic/'+str(a)+'/'
for t in tittle:
print('开始上传:'+t)
for page_img in range(int(page)):
download_img_url=download_url+str(page_img)+'.jpg'
thread=myThread(download_img_url,t,page_img)
thread.start()
threads.append(thread)
for ts in threads:
ts.join()
def upload_img(page,tittle):
print(tittle[0])
for i in range(int(page)):
file_s='temp/'+str(i)+'.jpg'
print(file_s)
b=upload(formatSource(file_s))
os.remove(file_s)
img_hc='<img src="'+b['image']['url']+'">'
with open('temp/temp.txt','a+') as f:
f.write(img_hc)
def post_article(info,tittle):
with open('temp/log.txt','a+') as f:
f.write(str(info)+'\n')
with open('temp/temp.txt','r') as f:
wz_content=f.read()
os.remove('temp/temp.txt')
a=wordpress_post(str(tittle[0]),wz_content)
conn=a.mysql_con()
cursor = conn.cursor()
c=a.up()
effect_row = cursor.execute(c)
new_id = cursor.lastrowid
d=a.cat(new_id,'1')
effect_row = cursor.execute(d)
a.close_mysql(cursor,conn)
def main():
flag=1
while True:
try:
info_s=get_page_url_info(flag)
except:
print('获取初始信息错误')
continue
for info in info_s:
img_info=[]
img_tittle=[]
img_page=[]
with open('temp/log.txt','r') as f:
b=f.read()
if info not in b:
try:
img_info=get_page_img_info(info)
except:
print('获取图片信息出错')
continue
img_tittle=img_info[0]
img_page=img_info[1]
try:
print('下载图片完成')
get_img(info,img_page[0],img_tittle)
except:
print('下载图片出错')
continue
try:
upload_img(img_page[0],img_tittle)
except:
print('图床错误')
continue
post_article(info,img_tittle)
else:continue
flag+=1
print('下一页')
if __name__=='__main__':
try:
if os.path.exists('temp')==False:
os.makedirs('temp')
f=open('temp/log.txt','w+')
f.close()
main()
else:
main()
except e:
print(e)
print('主程序出错,请重新运行')
要注意的是此爬虫仅支持python3;
需要的地方还有两个,一个是代码11行的数据库信息配置,也就是你的wordpress网站的数据库配置参数,另一个就是Chevereto图床的api key,这个key在图床后台的这里:
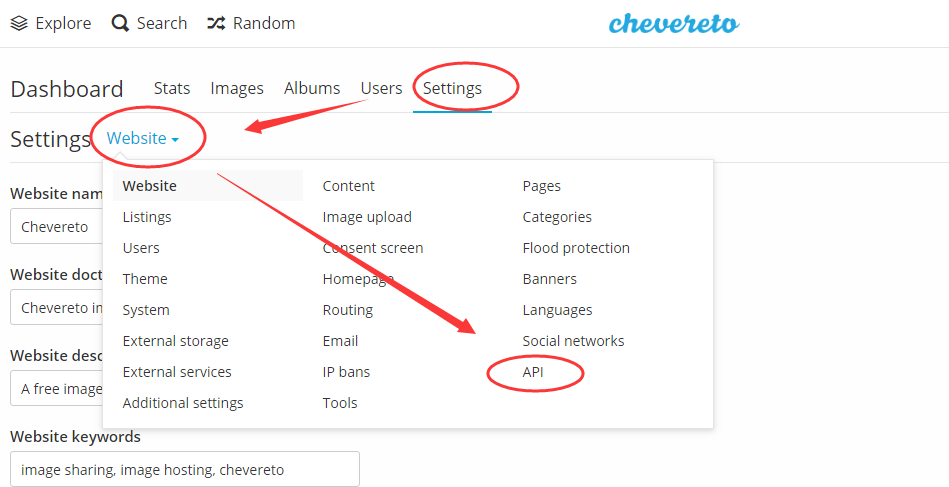
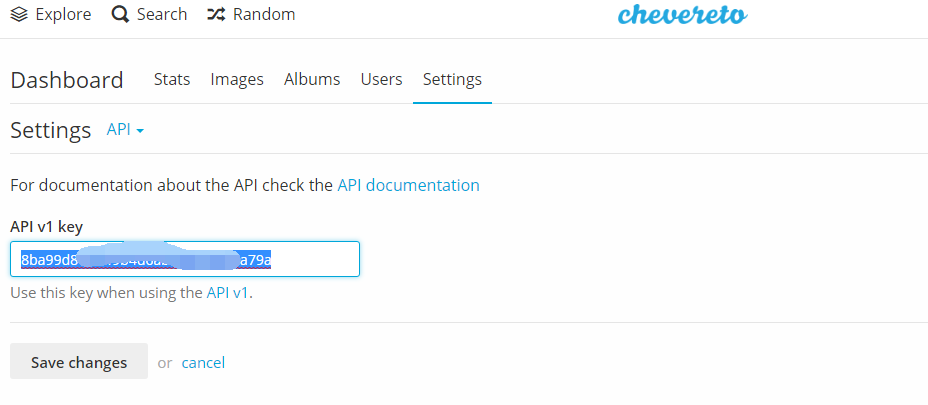
点击“API”;
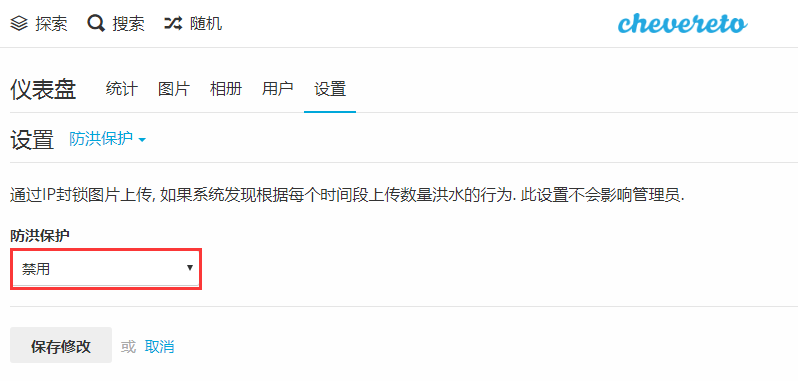
还有一点是禁用图床的防洪保护:
请自行准确填写相关配置,填好后,再安装Python 爬虫依赖的模块requests、pymysql:
pip install request pip install pymysql
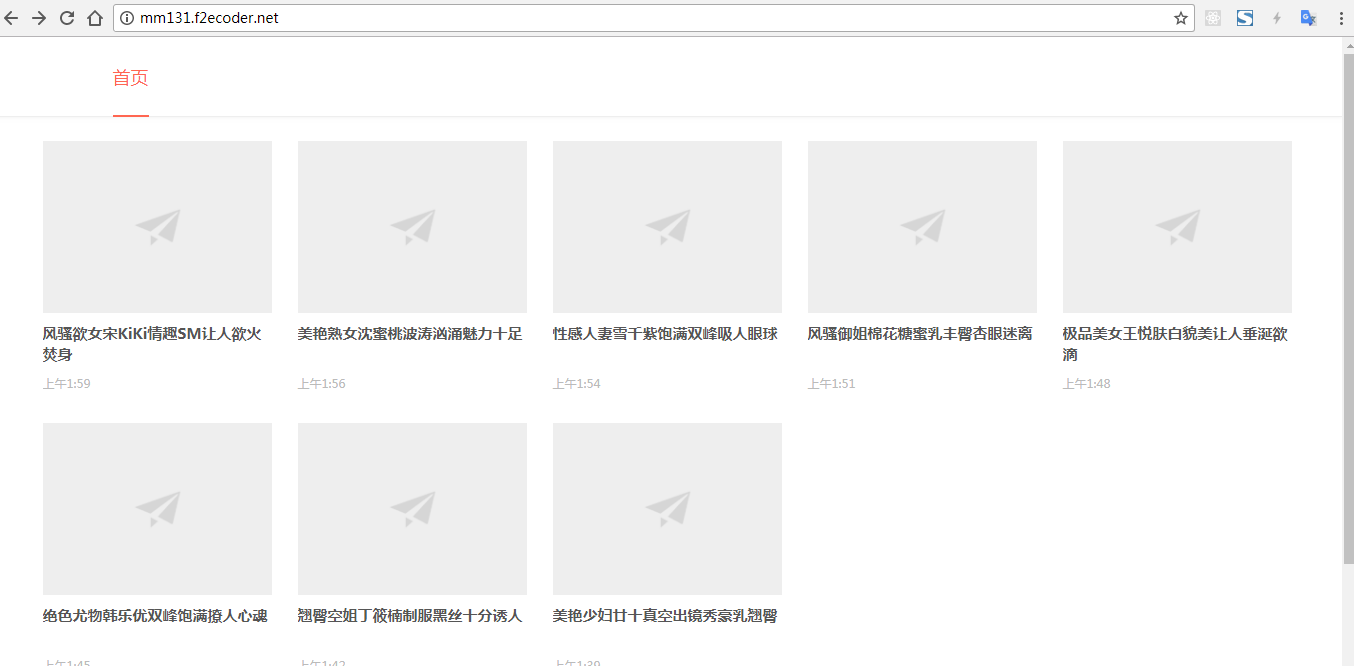
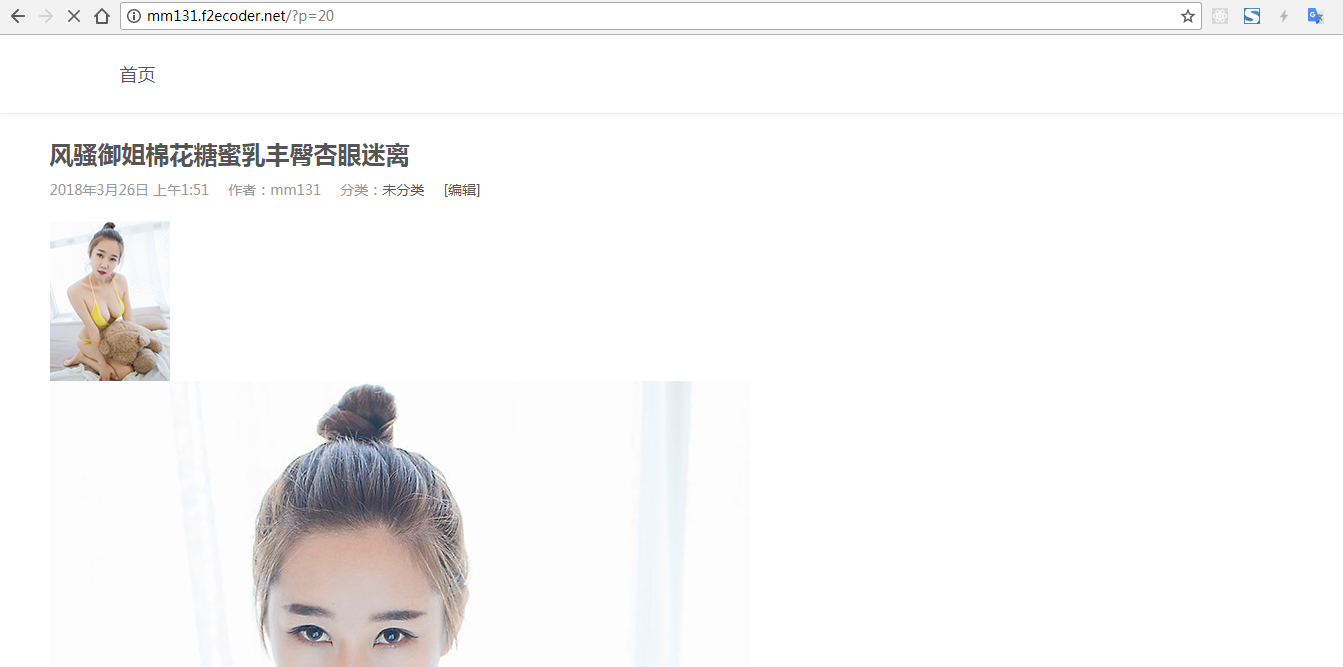
这些模块,都安装好后就可以在你的vps运行爬虫程序了,wordpress图片网站(top主题)的效果如下:
程序运行时可能看到后台有报错提示:
pymysql.err.InternalError: (1130, "Host '140.*.*.137' is not allowed to connect to this MySQL server")
解决办法如下:
以root用户进入mysql,然后分别执行下面两个命令:
GRANT ALL PRIVILEGES ON *.* TO '数据库用户名'@'%' IDENTIFIED BY '数据库用户密码' WITH GRANT OPTION; FLUSH PRIVILEGES;
源码下载地址:链接: https://pan.baidu.com/s/13EzYepkiSQdJs2wx6TAO3A 密码: yyjy
